大数据技术框架有哪些
大数据技术框架:从Hadoop到Spark,探索数据处理的未来
随着信息时代的来临,数据量的爆炸性增长使得传统的数据处理方法已经无法满足日益增长的需求。在这样的背景下,大数据技术框架应运而生,为处理海量数据提供了强大的工具和平台。从最早的Hadoop到如今的Spark,大数据技术框架不断演进,以适应不断变化的数据处理需求。
1. Hadoop
Hadoop是大数据处理的先驱,由Apache基金会开发。它包括两个核心模块:分布式文件系统HDFS和分布式计算框架MapReduce。Hadoop的优势在于它的可靠性和可扩展性,能够处理PB级别的数据,并且具备容错机制,即使在节点故障时也能保证任务的完成。
然而,Hadoop也存在一些局限性,例如MapReduce的计算模型不够灵活,无法有效处理迭代计算等复杂任务。因此,随着数据处理需求的变化,新的技术框架应运而生。
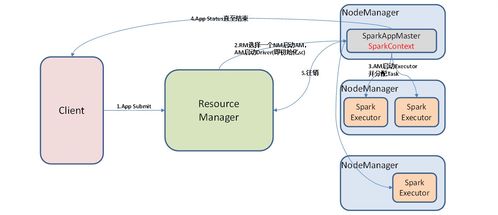
2. Spark
Spark是一种基于内存的分布式计算框架,由加州大学伯克利分校开发,并于2010年成为Apache顶级项目。相比于Hadoop的MapReduce,Spark具有更高的性能和更丰富的功能。
Spark的核心是弹性分布式数据集(RDD),它允许在内存中高效地处理数据,并支持迭代计算、流式处理、机器学习等多种计算模型。Spark提供了丰富的API,包括Scala、Java、Python和R,使得开发者可以用自己熟悉的语言进行大数据处理。
3. Flink
Apache Flink是另一个流行的大数据处理框架,它专注于流式处理,支持高吞吐量和低延迟的数据处理。与Spark相比,Flink更适合处理实时数据流,能够在保证数据一致性的同时提供低延迟的计算结果。
Flink的另一个优势是其对事件时间的支持,能够处理乱序事件并保证结果的准确性。这使得Flink在处理实时数据分析和复杂事件处理方面具有显著的优势。
4. Kafka
虽然Kafka并不是传统意义上的大数据处理框架,但它在大数据生态系统中扮演着至关重要的角色。Kafka是一种分布式流处理平台,用于发布和订阅数据流,并能够以高吞吐量、低延迟地进行消息传输。
Kafka常用于构建实时数据管道,将数据从生产者传输到消费者,并与其他大数据处理框架(如Spark、Flink等)集成,实现端到端的数据处理流程。
5. 总结和展望
大数据技术框架的发展历程呈现出不断演进的趋势,从最初的Hadoop到如今的Spark、Flink和Kafka,每一代技术都在不同的方面进行了创新和突破。未来,随着人工智能、物联网等新兴技术的发展,大数据处理的需求将会进一步增长,而大数据技术框架也将会不断地演进和完善,以应对日益复杂的数据处理挑战。
标签: 大数据技术框架 大数据应用的技术框架教程 大数据技术方案框架图 大数据技术框架有哪些 大数据框架类型有哪些
相关文章
-
模糊数学模型,解锁复杂问题的智慧钥匙详细阅读

在现实世界中,许多问题并不像传统数学那样清晰明了,如何定义“高个子”?是180厘米以上算高,还是175厘米也勉强可以称为高?这种模糊性在日常生活中无处...
2026-05-10 2
-
全面解析Win10升级工具,如何轻松完成系统升级?详细阅读

在当今数字化时代,操作系统是连接用户与硬件设备的核心桥梁,Windows 10(简称Win10)作为微软推出的一款广受欢迎的操作系统,以其稳定性、兼容...
2026-05-10 4
-
一键放大你的世界,窗口最大化的妙用与隐藏力量详细阅读

从一块小屏幕到无限可能想象一下,你正在厨房里做一道复杂的菜,手边有一本食谱,但它的字体太小,页面又窄,你不得不频繁翻页才能找到下一步该做什么,这时,如...
2026-05-10 6
-
探索未来网络世界的大门—思科网络技术学院详细阅读

在当今这个数字化飞速发展的时代,网络已经成为我们生活中不可或缺的一部分,无论是工作、学习还是娱乐,几乎每一件事都离不开互联网的支持,而在这背后,有一群...
2026-05-10 5
-
计算机网络技术及应用,从基础到未来趋势的全面解析详细阅读

在当今信息化时代,计算机网络技术已经成为现代社会的重要支柱之一,无论是日常生活中的社交媒体、在线购物,还是企业中的云计算、大数据分析,都离不开计算机网...
2026-05-09 6
-
轻松掌握LEFT函数,从入门到精通的实用指南详细阅读

什么是LEFT函数?LEFT函数是Excel中的一个文本函数,它的作用是从一个字符串的开头开始提取指定数量的字符,LEFT函数就像是一个“裁缝”,它会...
2026-05-09 5
-
透明Flash模块,数字世界中的隐形魔术师详细阅读

引言:什么是透明Flash模块?在当今数字化时代,技术的每一个细节都像是一块拼图,共同构建了我们所依赖的现代生活,而在这无数的技术组件中,“透明Fla...
2026-05-09 6
-
3GPP播放器全解析,功能、优势与实用指南详细阅读

什么是3GPP播放器?在数字化媒体和移动通信高速发展的今天,视频和音频文件的格式种类繁多,3GPP(Third Generation Partners...
2026-05-09 7