大数据面试专业问题分析怎么写
解析大数据面试专业问题
大数据领域在当今科技行业中扮演着至关重要的角色,因此,针对大数据的面试问题通常涉及广泛的主题,包括数据处理、分析、存储、可视化和机器学习等。下面我将分析几个常见的大数据面试专业问题,并提供相应的解答。
1. 什么是大数据?
大数据指的是规模巨大、类型繁多且增长迅速的数据集合,常常超出传统数据库处理能力的范围。大数据具有三个特点:
大量性
(Volume)、多样性
(Variety)和高速性
(Velocity)。它们可能包括结构化数据(如数据库中的数据)、半结构化数据(如 XML、JSON)和非结构化数据(如文本、图像、视频)。2. 请谈谈您对Hadoop的理解。
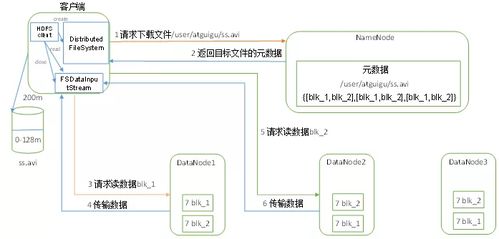
Hadoop是一个开源的分布式存储和计算平台,用于处理大规模数据集。它主要由Hadoop分布式文件系统(HDFS)和MapReduce计算框架组成。HDFS负责在廉价的硬件上存储大数据集,提供高容错性。而MapReduce框架则用于在集群上并行处理这些数据。除了核心组件外,Hadoop生态系统还包括各种工具和项目,如Hive、Pig、Spark等,用于简化大数据处理的流程。
3. 什么是MapReduce?它的工作原理是什么?
MapReduce是一种编程模型和处理大规模数据集的算法。它的工作原理基于两个主要阶段:Map和Reduce。在Map阶段,原始数据被拆分成小块,每个块由一个Mapper处理并生成一组键值对。在Reduce阶段,所有具有相同键的值被聚合在一起,然后由Reducer执行相应的操作(如求和、计数等)。这种分布式处理模型能够有效地利用集群中的资源,并实现高度的可扩展性。
4. 请解释一下Hive和Pig,它们的作用有何区别?
Hive和Pig是两种基于Hadoop的数据处理工具,它们都旨在简化大数据处理的过程。Hive提供了类似SQL的查询语言,允许用户使用类似于传统数据库的方式来查询和分析数据,它将这些查询转换为MapReduce任务并在集群上执行。Pig则提供了一种名为Pig Latin的脚本语言,用于描述数据处理流程,这些脚本会被编译成MapReduce任务或在Apache Tez等其他执行引擎上运行。总体而言,Hive更适合那些熟悉SQL的用户,而Pig更适合那些希望通过编写脚本来自定义数据处理流程的用户。
5. 什么是Spark?它与Hadoop有何不同?
Spark是另一个开源的大数据处理框架,与Hadoop相比,它具有更高的性能和更丰富的功能。Spark提供了一个名为RDD(Resilient Distributed Dataset)的抽象,它允许用户在内存中高效地进行数据处理,从而比传统的基于磁盘的MapReduce处理更快。Spark还提供了丰富的API,支持多种语言(如Scala、Java、Python)和各种处理任务(如批处理、流处理、机器学习等),使得它成为大数据处理的全能工具。
以上是一些大数据面试中常见的专业问题及其解答。掌握这些知识可以帮助应聘者在面试中展现自己的专业能力和理解。
标签: 大数据面试 大数据面试一般问什么 大数据面试专业问题分析怎么写 大数据面试题及答案
相关文章
-
深入理解DBF文件,你的数据存储老朋友详细阅读

在数字时代,数据是我们生活和工作的核心,无论是企业管理、科学研究还是个人事务,我们都离不开数据的记录和处理,而提到数据存储格式,许多人可能熟悉Exce...
2026-05-10 5
-
Dell交换机全解析,从入门到精通,打造高效网络架构详细阅读

在当今数字化转型的时代,网络基础设施的稳定性和性能直接影响企业的运营效率,而作为网络设备的核心组件之一,交换机的重要性不言而喻,我们将深入探讨Dell...
2026-05-10 5
-
模糊数学模型,解锁复杂问题的智慧钥匙详细阅读

在现实世界中,许多问题并不像传统数学那样清晰明了,如何定义“高个子”?是180厘米以上算高,还是175厘米也勉强可以称为高?这种模糊性在日常生活中无处...
2026-05-10 6
-
全面解析Win10升级工具,如何轻松完成系统升级?详细阅读

在当今数字化时代,操作系统是连接用户与硬件设备的核心桥梁,Windows 10(简称Win10)作为微软推出的一款广受欢迎的操作系统,以其稳定性、兼容...
2026-05-10 4
-
一键放大你的世界,窗口最大化的妙用与隐藏力量详细阅读

从一块小屏幕到无限可能想象一下,你正在厨房里做一道复杂的菜,手边有一本食谱,但它的字体太小,页面又窄,你不得不频繁翻页才能找到下一步该做什么,这时,如...
2026-05-10 6
-
探索未来网络世界的大门—思科网络技术学院详细阅读

在当今这个数字化飞速发展的时代,网络已经成为我们生活中不可或缺的一部分,无论是工作、学习还是娱乐,几乎每一件事都离不开互联网的支持,而在这背后,有一群...
2026-05-10 5
-
计算机网络技术及应用,从基础到未来趋势的全面解析详细阅读

在当今信息化时代,计算机网络技术已经成为现代社会的重要支柱之一,无论是日常生活中的社交媒体、在线购物,还是企业中的云计算、大数据分析,都离不开计算机网...
2026-05-09 6
-
轻松掌握LEFT函数,从入门到精通的实用指南详细阅读

什么是LEFT函数?LEFT函数是Excel中的一个文本函数,它的作用是从一个字符串的开头开始提取指定数量的字符,LEFT函数就像是一个“裁缝”,它会...
2026-05-09 5